声明:本文章根据 小林coding 图解mysql进行些许改编。侵权删。本文持续更新。
索引篇
什么是索引
当你想查阅书中某个知识的内容,你会选择一页一页的找呢?还是在书的目录去找呢?
傻瓜都知道时间是宝贵的,当然是选择在书的目录去找,找到后再翻到对应的页。书中的目录,就是充当索引的角色,方便我们快速查找书中的内容,所以索引是以空间换时间的设计思想。
那换到数据库中,索引的定义就是帮助存储引擎快速获取数据的一种数据结构,形象的说就是索引是数据的目录。
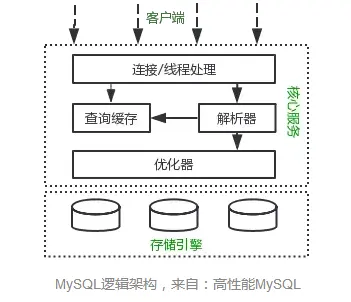
下图是 MySQL 的结构图,索引和数据就是位于存储引擎中:
索引分类
按「数据结构」分类
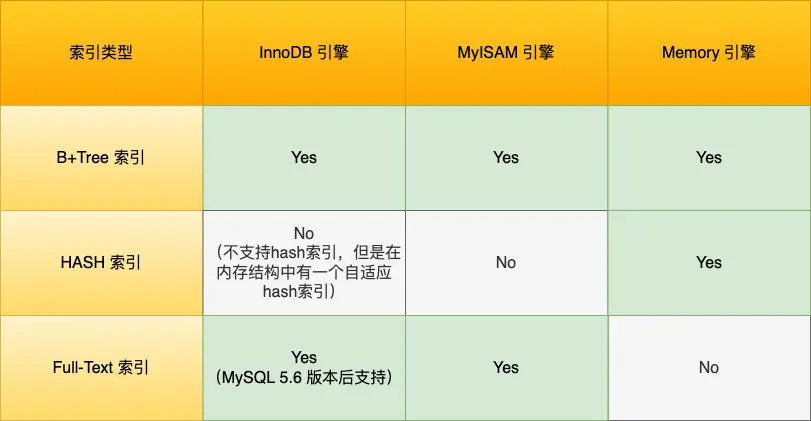
- B+tree索引、Hash索引、Full-text索引。
按「物理存储」分类
聚簇索引(主键索引)、二级索引(辅助索引)。
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
所以,在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表。
按「字段特性」分类
- 主键索引、唯一索引、普通索引、前缀索引。 唯一约束(UNIQUE KEY)就是一种索引 所以主键就是索引。。
ON DUPLICATE KEY UPDATE
提供无则插入、有则更新 的原子性upsert命令,避免先查再写的并发问题。 常用于实现幂等写入,但不属于乐观锁。
MySQL 在执行 INSERT ... ON DUPLICATE KEY UPDATE 后,会返回一个整数值告诉你有多少行被影响了。
规则如下(重要,正是因为这里容易错):
| 实际发生的情况 | affected_rows | 说明 |
|---|---|---|
| 真正插入了一条新记录 | 1 | 原来没有这行,插入成功 |
| 更新了一条记录,并且数据真的被修改了 | 2 | 冲突后走 UPDATE,且字段值确实变了 |
| 更新了一条记录,但数据没有任何变化 | 0 | 冲突后走 UPDATE,但 SET 后的值和原来一样 |
按「字段个数」分类
- 单列索引、联合索引。
B+Tree
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
图有误,叶子节点是双向链表
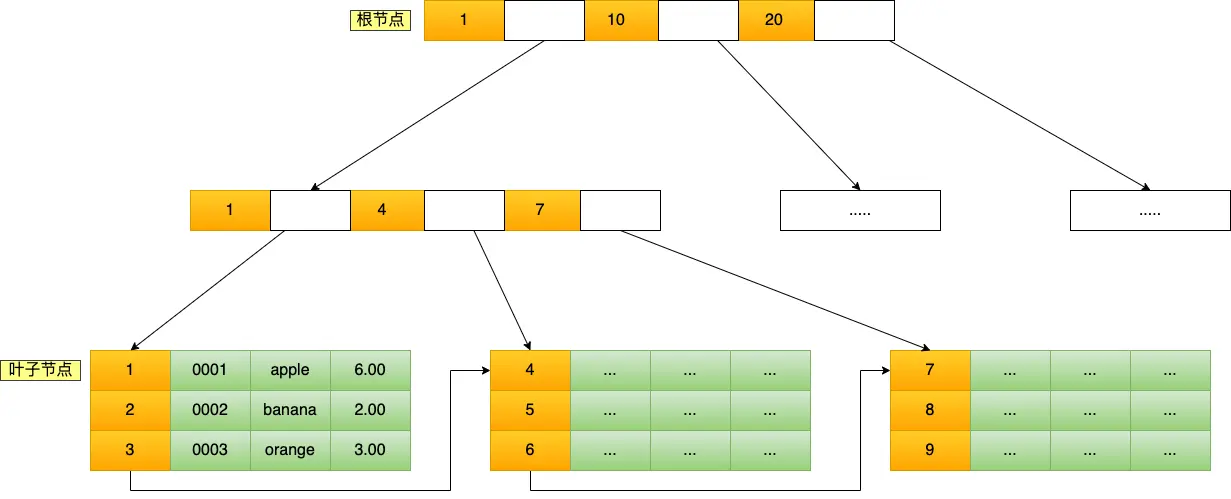
通过主键查询商品数据的过程:
比如,我们执行了下面这条查询语句:
1select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
- 将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
分页方式
普通分页
用 页码 翻页(第 1 页、第 2 页),SQL 用 OFFSET
1-- 第1页(最新10条)
2SELECT * FROM video
3ORDER BY create_time DESC
4LIMIT 10;
5
6-- 第2页(跳过10条,取10条)
7SELECT * FROM video
8ORDER BY create_time DESC
9OFFSET 10 LIMIT 10;
10
11-- 第3页(跳过20条,取10条)
12SELECT * FROM video
13ORDER BY create_time DESC
14OFFSET 20 LIMIT 10;
缺点:
- 刷到重复 / 漏视频 刷第 2 页时,有人发了新视频 → 第 2 页数据会乱,要么重复刷到,要么漏掉
- 越翻越慢,直接卡死数据库
翻到第 1000 页:
OFFSET 10000 LIMIT 10MySQL 要先扫描 10000 条数据,再扔掉,只取 10 条,数据量大直接崩库 - 不适合无限下拉 抖音没有「第 10 页」,只有「一直往下刷」
游标分页
用 上次刷到的位置 翻页(接着上次继续刷),SQL 不用 OFFSET,用 WHERE 条件
1-- 第一次下拉(无游标,查最新10条)
2SELECT * FROM video
3ORDER BY create_time DESC
4LIMIT 10;
5
6-- 第二次下拉(带着游标,直接查比这个时间更早的10条)
7SELECT * FROM video
8WHERE create_time < 1716200000 -- 用游标做条件,不用OFFSET
9ORDER BY create_time DESC
10LIMIT 10;
- 不重复、不漏视频 不管发多少新视频,永远接着上次的位置刷
- 速度快,不卡死
没有
OFFSET,MySQL 直接靠索引定位位置,只查 10 条数据 - 适配无限下拉
还可以进一步变成复合游标分页。
1 -- 热度榜:popularity + create_time + id
2 WHERE (popularity < ?) OR (popularity = ? AND create_time < ?) OR (popularity = ? AND create_time = ? AND id < ?)
3 -- 点赞榜:likes_count + id
4 WHERE (likes_count < ?) OR (likes_count = ? AND id < ?)
从普通分页 → 游标分页 → 复合游标分页,就是一步步消除排序歧义,最终实现绝对确定性排序、绝对稳定分页。
事务篇
事务隔离级别
事务的ACID特性
ACID:原子性、一致性、隔离性、持久性
InnoDB 引擎通过什么技术来保证事务的这四个特性的呢?
- 持久性是通过 redo log (重做日志)来保证的;
- 原子性是通过 undo log(回滚日志) 来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
- 一致性则是通过持久性+原子性+隔离性来保证;
这次将重点介绍事务的隔离性 为什么事务要有隔离性,我们就要知道并发事务时会引发什么问题。
并行事务导致的三个问题
脏读
如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。
- A 改了还没提,B 就看见了。如果 A 回滚了,B 就看了一条假数据。
- 注:Postgres 实际上不支持这个级别,它最低就是 Read Committed,所以 Postgres 里永远不会发生脏读。(mysql支持这个隔离级别)
不可重复读
在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,就意味着发生了「不可重复读」现象。
- B 在一个事务里查了两次余额。第一次 100。中间 A 改成 200 并提交了。B 第二次查变成 200。
- 影响:同一个事务里,同样的 SQL 查出来的结果不一样。
幻读
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
换句话说:所谓的幻读是指在同一事务下,连续执行两次同样的查询语句,第二次的查询语句可能会返回之前不存在的行。幻觉了。。
- B 统计总人数是 5。中间 A 插入了一个新用户。B 再统计(或做全表操作)时发现莫名其妙多了一行。
- 区别:“不可重复读”是看一行数据变了;“幻读”是数据总量/集合变了。

读未提交(READ UNCOMMITTED)
- 现象:能读到其他事务还没提交的数据
- 问题:脏读、不可重复读、幻读 全都有
- 实现:不加锁 + 不用 MVCC
- 直接读取最新数据,不管事务有没有提交
- 性能最高,但最不安全
读已提交(READ COMMITTED)
- 现象:只能读到其他事务已经提交的数据
- 解决:脏读
- 残留问题:不可重复读、幻读
- 实现:MVCC(多版本并发控制)
- 每次 SELECT 都会生成新的 Read View
- 只看 “已提交” 的数据版本
- 读写不阻塞,高并发
可重复读(REPEATABLE READ)
MySQL 默认隔离级别!
- 现象:一个事务内,多次读取同一数据,结果完全一样
- 解决:脏读、不可重复读
- 残留问题:普通幻读解决,极端幻读仍可能存在
- 实现:
- MVCC(Read View 只生成一次)
- 事务开始时生成一个 Read View,全程复用
- 保证整个事务看到的数据版本一致
- 间隙锁(Gap Lock)+ 临键锁(Next-Key Lock)
- 用来防止幻读
- 锁定一个范围,不让其他事务插入数据
- MVCC(Read View 只生成一次)
串行化(SERIALIZABLE)
- 现象:所有事务排队执行,完全串行
- 解决:脏读、不可重复读、幻读 全部解决
- 问题:并发性能极差
- 实现:强制加锁
- 读加共享锁,写加排他锁
- 读写互相阻塞,变成串行执行
锁篇
全局锁
1flush tables with read lock
执行后,整个数据库就处于只读状态了,这时其他线程执行以下操作,都会被阻塞:
- 对数据的增删改操作,比如 insert、delete、update等语句;
- 对表结构的更改操作,比如 alter table、drop table 等语句。
如果要释放全局锁,则要执行这条命令:
1unlock tables
表级锁
表锁
如果我们想对学生表(t_student)加表锁,可以使用下面的命令:
1//表级别的共享锁,也就是读锁;
2//允许当前会话读取被锁定的表,但阻止其他会话对这些表进行写操作。
3lock tables t_student read;
4
5//表级别的独占锁,也就是写锁;
6//允许当前会话对表进行读写操作,但阻止其他会话对这些表进行任何操作(读或写)。
7lock tables t_stuent write;
需要注意的是,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作。
举个例子, 如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
要释放表锁,可以使用下面这条命令,会释放当前会话的所有表锁:
1unlock tables
行级锁
行级锁的类型主要有三类:
- Record Lock,记录锁,也就是仅仅把一条记录锁上;
- Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
- Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
什么 SQL 语句会加行级锁?
InnoDB 引擎是支持行级锁的,而 MyISAM 引擎并不支持行级锁,所以后面的内容都是基于 InnoDB 引擎 的。
所以,在说 MySQL 是怎么加行级锁的时候,其实是在说 InnoDB 引擎是怎么加行级锁的。
普通的 select 语句是不会对记录加锁的(除了串行化隔离级别),因为它属于快照读,是通过 MVCC(多版本并发控制)实现的。
如果要在查询时对记录加行级锁,可以使用下面这两个方式,这两种查询会加锁的语句称为锁定读
1//对读取的记录加共享锁(S型锁)
2select ... lock in share mode;
3
4//对读取的记录加独占锁(X型锁)
5select ... for update;
上面这两条语句必须在一个事务中,因为当事务提交了,锁就会被释放,所以在使用这两条语句的时候,要加上 begin 或者 start transaction 开启事务的语句。
除了上面这两条锁定读语句会加行级锁之外,update 和 delete 操作都会加行级锁,且锁的类型都是独占锁(X型锁)。
1//对操作的记录加独占锁(X型锁)
2update table .... where id = 1;
3
4//对操作的记录加独占锁(X型锁)
5delete from table where id = 1;
共享锁(S锁)满足读读共享,读写互斥。独占锁(X锁)满足写写互斥、读写互斥。
Record Lock
Record Lock 称为记录锁,锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的:
- 当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容);
- 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
举个例子,当一个事务执行了下面这条语句:
1mysql > begin;
2mysql > select * from t_test where id = 1 for update;
就是对 t_test 表中主键 id 为 1 的这条记录加上 X 型的记录锁,这样其他事务就无法对这条记录进行修改了。
当事务执行 commit 后,事务过程中生成的锁都会被释放。
Gap Lock
Gap Lock 称为间隙锁,存在于可重复读隔离级别和串行化隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
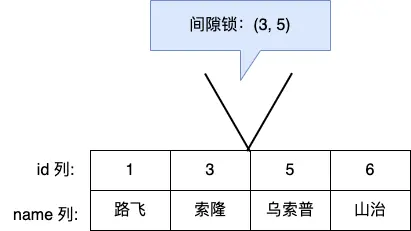
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
Next-Key Lock
Next-Key Lock 称为临键锁,是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
假设,表中有一个范围 id 为(3,5] 的 next-key lock,那么其他事务即不能插入 id = 4 记录,也不能修改 id = 5 这条记录。