本文持续更新
堆、栈
它们是程序运行时,两块用途完全不同的内存区域。
栈(Stack)—— 函数的临时小抽屉
- 每个函数运行时,都会在栈上占一小块空间;
- 函数里的局部变量、参数默认都往栈上放;
- 函数一结束,栈空间自动清空,变量直接销毁;
- 速度极快,几乎零开销;
- 不需要 GC 垃圾回收。
特点:自动申请、自动释放,快、小、临时。
堆(Heap)—— 全局公共大仓库
- 一块共享的大内存;
- 放那些函数结束后还需要活着的变量;
- 不会自动销毁,靠 Go 的 GC 来回收;
- 分配慢、寻址慢、有 GC 开销。
特点:手动 / 编译器决定分配,GC 回收,慢、大、持久。
在栈还是堆
直接用 Go 自带的逃逸分析命令看:
1go build -gcflags="-m" main.go
输出里会出现两种关键行:
does not escape→ 变量在 栈 上escapes to heap→ 变量逃逸到 堆 上
slice
数据结构
slice是引用类型,共享内存地址
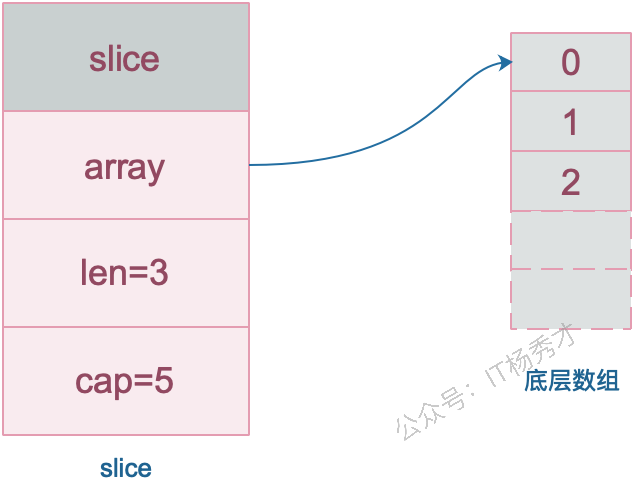
切片扩容
只有append才会触发扩容!手动make只是新建切片。
扩容会彻底替换底层数组:
- 计算新的容量(按增长规则)
- 在堆上新建一个更大的底层数组
- 把旧数组的所有数据完整拷贝到新数组
- 切片指针指向新数组,更新
len/cap - 旧数组如果没有其他引用,会被 GC 自动回收
容量增长规则(Go 1.18+ 最新版)
小切片快速扩容,大切片平缓扩容,避免内存浪费
| 旧容量大小 | 扩容规则 | 示例 |
|---|---|---|
| < 256 | 直接 翻倍 容量 | 100 → 200 |
| ≥ 256 | 增长~1.375 倍(平缓) | 300 → 412 |
常见误区
Q: 从一个切片截取出另一个切片,修改新切片的值会影响原来的切片内容吗? A: 直接截取生成的新切片,和原切片共享底层数组 → 修改新切片的值,会影响原切片 如果新切片触发了扩容(append 超出容量),就会脱离共享 → 修改不再影响原切片
并发不安全
和 map 一样,Go 语言中的切片天生不支持多协程并发读写,多协程同时操作切片会直接导致数据错乱、程序 panic、内存非法访问。因为所有修改切片的操作(append / 赋值 / 扩容),都需要分步修改多个字段,无法一步完成所以无法满足原子性。
map
2的幂次桶数组 + 单桶8个kv + 溢出桶拉链 + 渐进式哈希表
map底层实现原理
- Go map 底层是哈希表(Hash Table)
- map 是引用类型,底层数据存在堆上
- 函数传参是值传递(拷贝 map 头部指针,共享底层数据)
- 无序、并发不安全、自动扩容
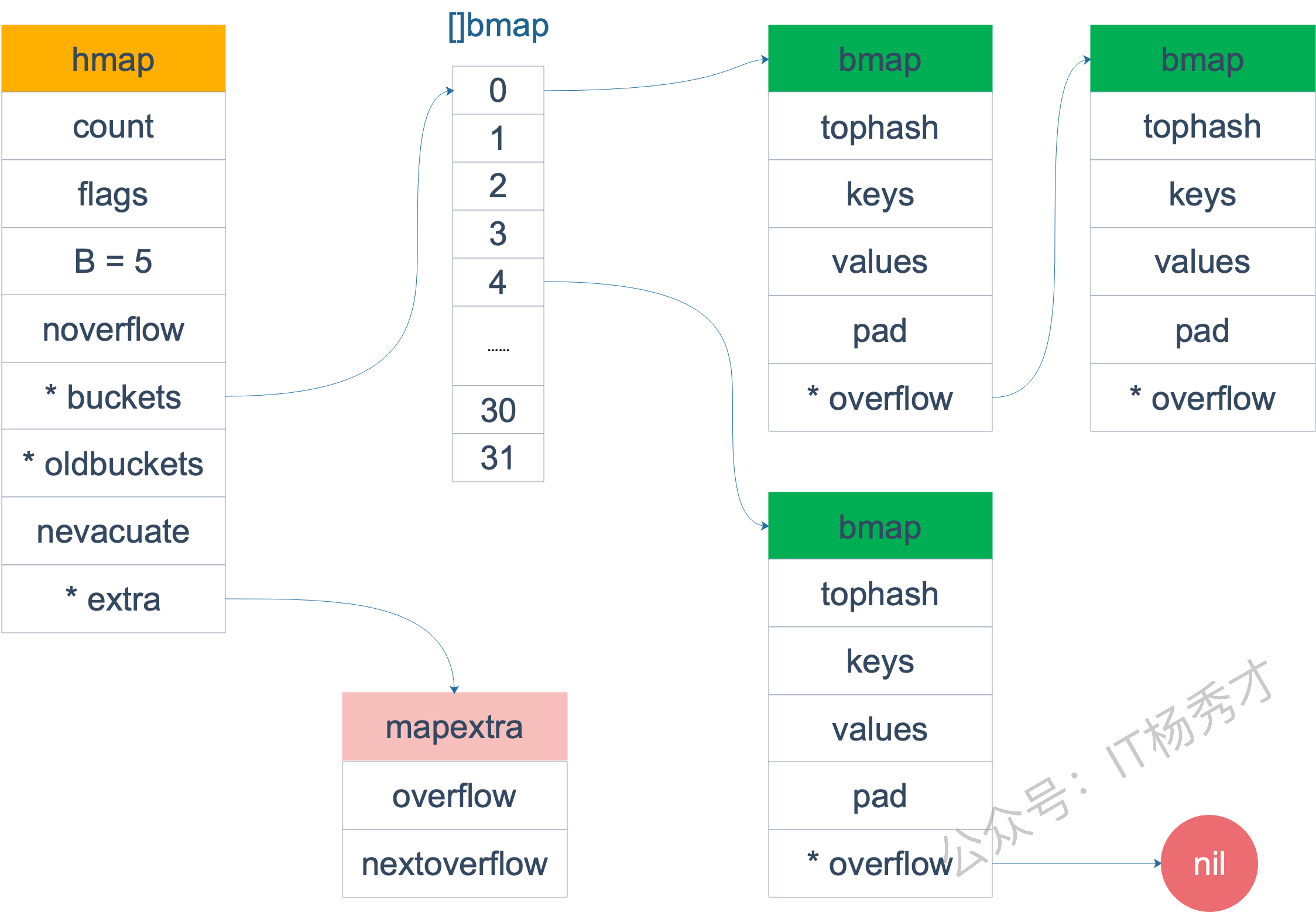
桶(bmap)
- 1 个桶 = 能存 8 个键值对
- 桶满了 → 创建溢出桶(overflow bucket),用链表串起来(处理哈希冲突的方法是链表法)
- 所有数据最终都存在桶中,桶存在堆空间,所以map是引用类型
1哈希表结构:
2hmap (头部) → [桶0][桶1][桶2][桶3]... (桶数组)
3 ↓
4每个桶:[key/val][key/val][key/val]... (最多8个) → 溢出桶 → ...
查找流程:
以 m["key"] = 10 为例:
- 计算哈希值 对 key 做哈希运算,得到一个哈希码
- 定位桶 用哈希码 低 B 位 计算:这个 key 应该放在第几个桶
- 查找空位 遍历当前桶 + 溢出桶:
- 找到相同 key → 覆盖值
- 没找到 → 找空位写入
- 读取数据 和写入流程完全一样,定位桶 → 匹配 key → 取值
map遍历
go语言里Map的遍历是完全随机的。那要如何实现顺序读取? 可以讲Map的key取出来放在一个slice中,用sort包对slice进行排序,然后再去遍历。
天然去重
哈希表的规则就是: 同一个key,永远只会对应同一个位置 不同的key,必须对应不同位置
所以map的键不能重复。这也是为什么map很适合作为set的模拟。
自动扩容机制
map 不会一直塞满,达到阈值就自动扩容,保证读写速度。
扩容触发条件
- 负载因子 > 6.5(平均每个桶存了超过 6.5 个元素)
- 溢出桶数量太多
扩容方式
- 翻倍扩容:桶数量 ×2,重新分配所有 key(最常用)
- 等量扩容:整理溢出桶,不改变数量
扩容特点
- 渐进式扩容:不是一次性搬完,访问时逐步搬迁
- 对业务无感知,自动完成
并发不安全
不是不能并发,是官方主动阻止,防止出现不可预知的脏数据 / 野指针。
map 底层有一个标志位:hashWriting(标记是否正在写入)
规则:
- 开始写 → 标志置为 1
- 写完 → 标志置为 0
- 如果读的时候,发现标志是 1(正在写) → 直接 panic 崩溃
为什么这样设计?
- 设计上:为了单线程性能,默认不加锁;
- 底层上:读写是多步操作,非原子、会冲突;
- 安全上:官方检测到并发读写,直接 panic 保护数据。
如何使之并发安全?
- 自己加上读写锁sync.RWMutex
- go 1.9+支持sync.Map
sync.Map用法
| 方法 | 作用 |
|---|---|
Store(key, value any) | 存储键值对 |
Load(key any) (value any, ok bool) | 查询键值对,返回值 + 是否存在 |
LoadOrStore(key, value any) (actual any, loaded bool) | 存在则返回,不存在则存储 |
Delete(key any) | 删除键值对 |
LoadAndDelete(key any) (value any, loaded bool) | 加载并删除(原子操作) |
Range(f func(key, value any) bool) | 遍历所有键值对(返回 false 终止遍历) |
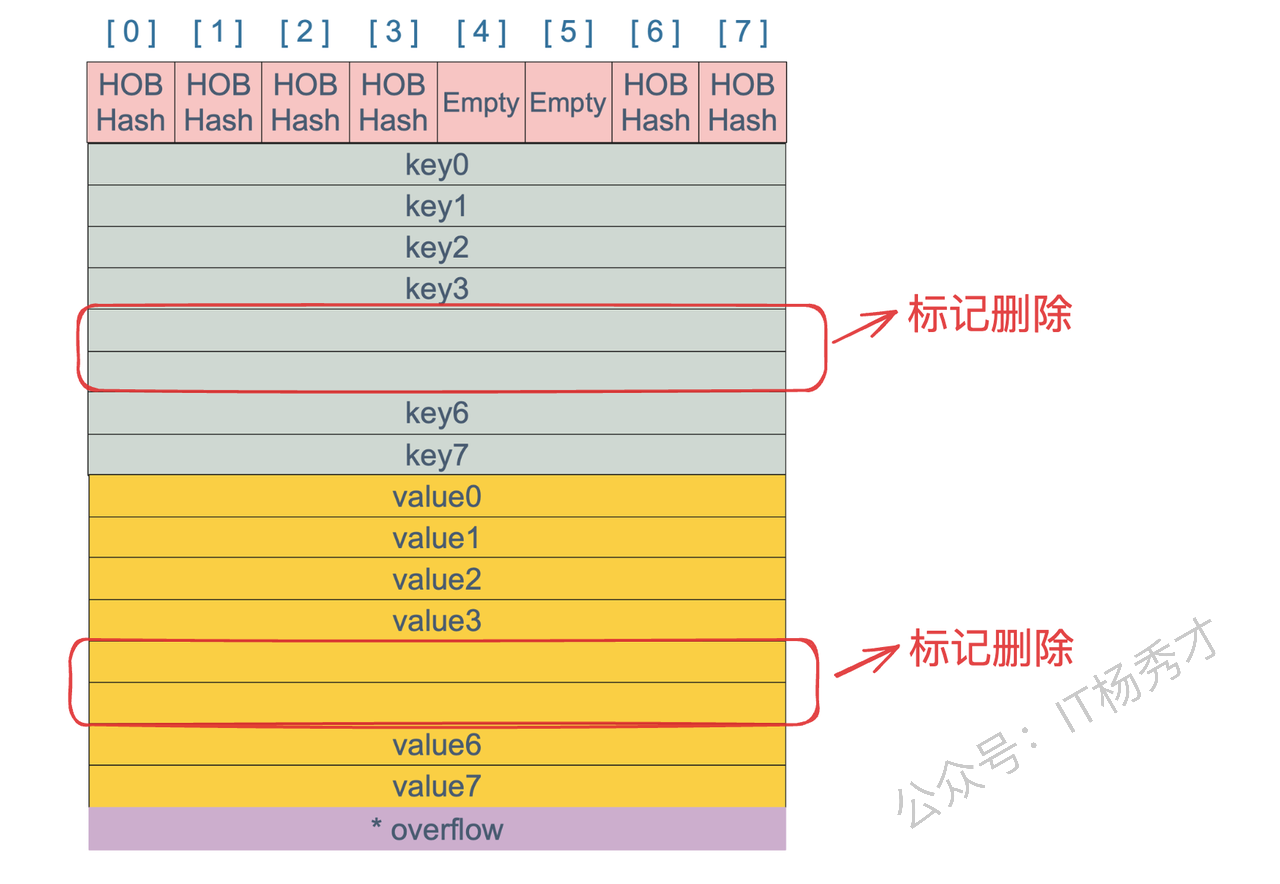
删除Key的过程做了什么事
只是在bmap中标记删除,等待GC处理,规模是不会缩小的。
channel
下面介绍golang里唯一内置天然并发安全的类型:channel 底层自带同步 / 阻塞机制,实现了先进先出的线程安全队列
底层实现原理
hchan的结构体是channel的底层,包括几个关键组件:
lock:互斥锁 → 所有读写操作加锁,这是并发安全的根源;buf:环形数组(环形缓冲区) → 有缓冲 Channel 的数据存储区;recvq/sendq:等待队列 → 存阻塞的发送 / 接收协程;closed:关闭标记。
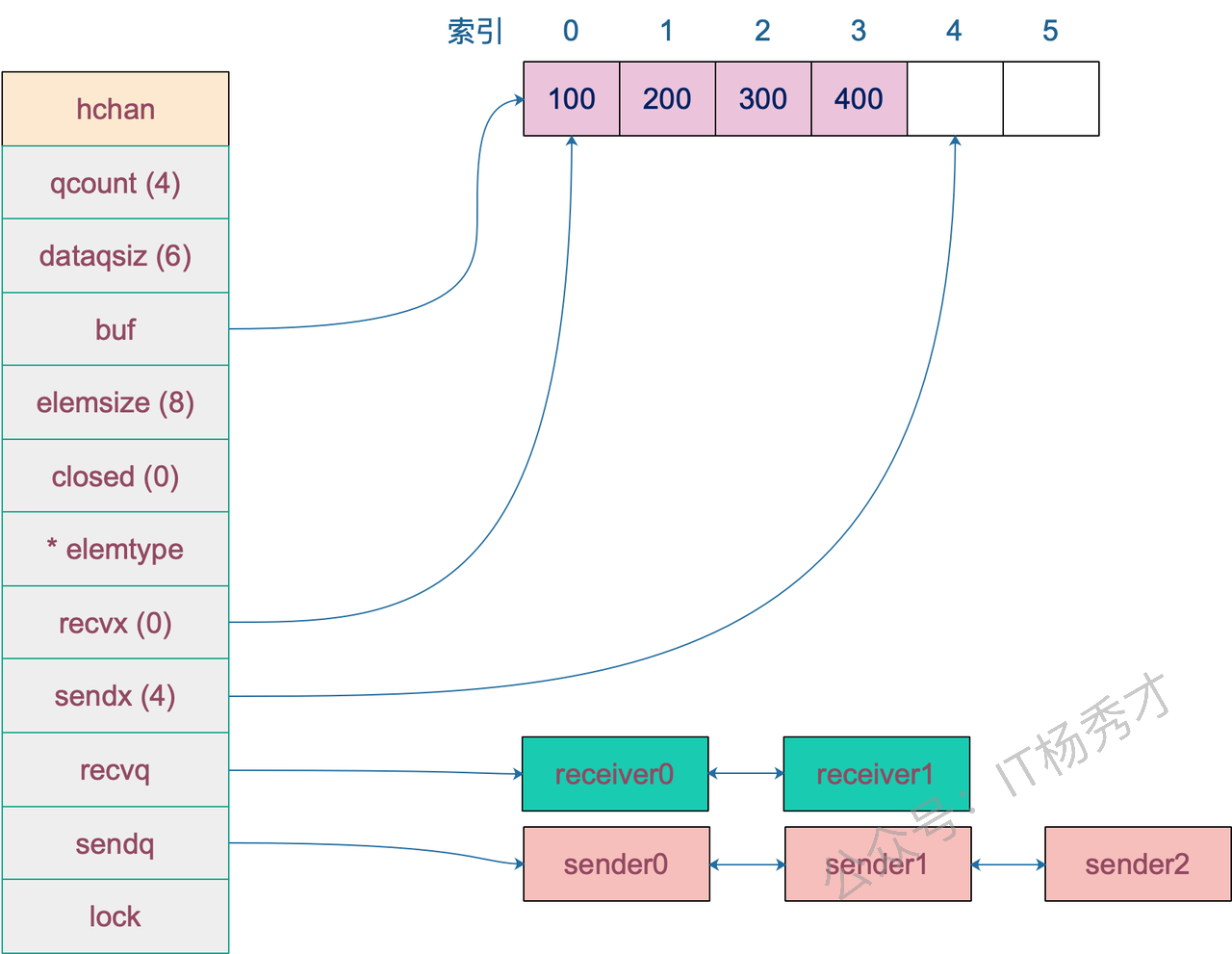
向channel发送数据的流程
- 首先检查是否有等待的接受者,最高效
- 如果没有阻塞接受者,就尝试写入缓冲区
- 缓冲区写不下了就要阻塞等待 被唤醒后继续执行1 向关闭的channel写入数据会panic
从channel接收数据的流程
- 首先检查是否有等待的发送者
- 对于无缓冲channel,直接从发送者处接收数据
- 对于有缓冲channel,先发送到缓冲区,保证FIFO
- 如果没有阻塞的发送者,就从缓冲区读取 缓冲区为空时需要阻塞等待 从已关闭的channel读取需要ok command语句判断是否成功
sudog
它不是给业务代码用的,是 Go 调度器 + channel 底层必须依赖的内部数据结构,属于 runtime 底层实现。
1type sudog struct {
2 g *g // 正在等待的那个 goroutine
3 elem unsafe.Pointer // 数据地址(channel 收发的数据存在这)
4 c *hchan // 等待的目标 channel
5 next *sudog // 链表:channel 里的等待队列是链表
6 prev *sudog
7}
| 角色 | 作用 |
|---|---|
| 等待节点 | 代表一个正在等待 channel 的 goroutine |
| 数据桥梁 | 存储 goroutine 要收发的数据 |
| 链表元素 | 组成 channel 的等待队列(sendq/recvq) |
| 调度凭证 | 调度器靠它找到并唤醒等待的 goroutine |
select
select是go语言专门为channel操作设计的多路复用控制结构,类似于网络编程中的select系统调用
核心思想是同时监听多个channel操作,当有多个channel都可能有数据收发时,select能选择其中一个可执行的(就绪的)case进行操作,而不是按顺序逐个尝试。比如同时监听数据输入、超时信号、取消信号等。
底层原理:
- case随机化以避免饥饿
- 双重循环检测
- 第一轮打乱顺序,检查每个channel是否可以读写,如果找到就绪的就立刻执行
- 都没就绪,进行第二轮,把当前select语句所在的goroutine打包成sudog,加入到所有channel的发送或接受队列中,调用gopark进入睡眠,使当前goroutine让出CPU
Sync
如何安全读写共享变量
Mutex、信号量、通道、原子操作
互斥锁Mutex的底层实现
mutex底层是通过原子操作加信号量实现的
1type Mutex struct {
2 state int32 // 锁状态:一个32位整数,用【位】存储所有信息
3 sema uint32 // 信号量:关联等待队列(存储 sudog)
4}
CAS原子抢锁
mutex用cas做无锁快速路径,如果cas抢锁成功就不用加锁,只有 CAS 失败后,才进入真正加锁的慢速路径
这是CPU 指令级的原子操作,能够保证只有锁空闲的时候,才能抢到锁 compare and swap 比较并替换:
- 读取
count = 5(old=5) - 想要要改成
6(new=6) - 执行 CAS:
- 检查内存里的
count还是不是5? - 是 → 改成
6,成功! - 不是(比如被别人改成 6 了)→ 失败,重新读取最新值,再试一次
- 检查内存里的
这种抢锁方式全程不加锁,性能高 是乐观锁的实现,用无锁方式实现了互斥
自适应自旋
抢不到锁时,不立刻挂起 goroutine,而是短暂循环重试(最多 4 次)。自旋比挂起调度轻得多,适合锁会快速释放的场景。
mutex有两种模式
正常模式
讲究性能,后面才来的请求锁的goroutine也可以与头部的goroutine竞争(通过自旋),但可能会导致头部goroutine等了很久,不公平。
饥饿模式
讲究公平,当一个goroutine等待超过1ms后,Mutex就会切换到这个模式,此时必须排队,不允许自旋。
信号量+sudog
自旋失败后,将 G 包装成 sudog 加入队列,把sudog放入sema对应的等待队列,挂起 G(让出 CPU),解锁时再唤醒。避免空转 CPU,提升调度效率。
在这一步里,信号量的作用是sema连接 Mutex 和等待队列
WaitGroup怎样实现协程等待
本质上是一个原子计数器和一个信号量的协作 Add会增加计数器值,Done会减计数值。Wait会检查计数器,如果不为零,就用信号量将当前goroutine高效挂起。直到最后一个Done将计数器清零,这个信号量会一次性唤醒所有在Wait处等待的goroutine。
1type WaitGroup struct {
2 noCopy noCopy
3
4 // Bits (high to low):
5 // bits[0:32] counter
6 // bits[32] flag: synctest bubble membership
7 // bits[33:64] wait count
8 state atomic.Uint64
9 sema uint32
10}
atomic包保证所有修改都是原子的
1┌───────────── 32位 ─────────────┬───────────── 32位 ─────────────┐
2│ 高32位:waiter │ 低32位:counter │
3│ 有多少个goroutine在Wait等待 │ 还没执行完的goroutine数量 │
4└────────────────────────────────┴────────────────────────────────┘
流程举例:
1var wg sync.WaitGroup
2wg.Add(2) // 1. counter +=2 → state低32位=2
3
4go func(){
5 defer wg.Done() // 3. counter -=1 → 低32位=1
6}()
7
8go func(){
9 defer wg.Done() // 4. counter -=1 → 低32位=0
10}()
11
12wg.Wait() // 2. waiter +=1(高32位=1),挂起当前协程
13 // 5. 发现counter=0 → 清空waiter,唤醒自己,继续执行
sync.Map底层实现
官方提供的并发安全的键值对映射表 空间换时间,通过read和dirty两个Map的冗余结构,实现了读写分离。这很类似与zookeeper的架构设计 适合于读多写少的场景 read是只读缓存,不一定是最新的。它保证最终一致性,不保证线性一致性与可串行化。
1type Map struct {
2 mu Mutex // 互斥锁:只保护 dirty map,锁粒度极小
3 read atomic.Value // 原子变量:存 read map(只读热点数据,无锁访问)
4 dirty map[any]*entry // 脏数据 map:存新写入的数据,需要加锁
5 misses int // 读未命中计数器:满了就升级 dirty 为 read
6}
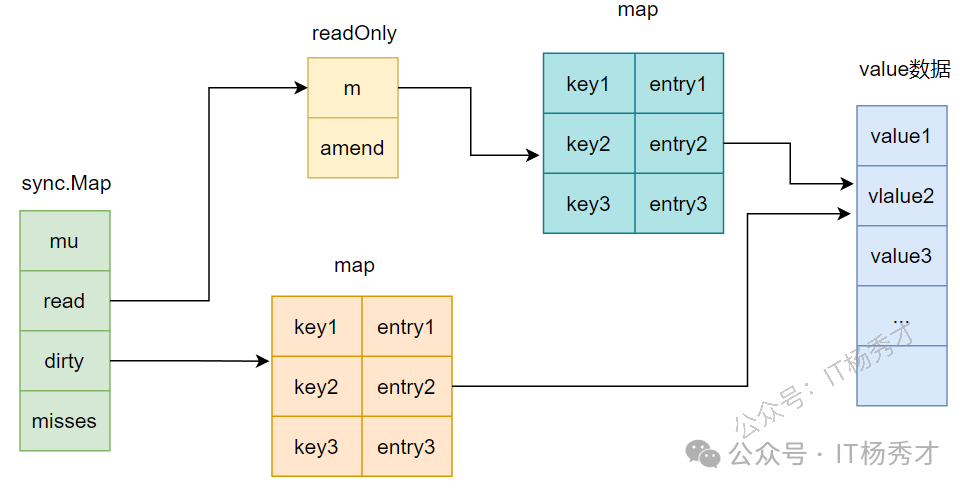
| 操作类型 | 优先访问 | 是否加锁 | 性能特点 |
|---|---|---|---|
| 读操作 | read map | ❌ 无锁 | 极高(原子操作) |
| 写操作 | dirty map | ✅ 加锁 | 一般(互斥锁保护) |
| 读流程: |
- 原子加载
read指针,获取readOnly结构体 - 查找 key,若存在且值未被删除,直接返回(无锁)
- 若不存在或已删除,检查
amended(是否有 dirty 新数据) - 若
amended为true,加锁访问dirty并递增misses - 若
misses达到阈值(len(dirty)),将dirty升级为read
写流程:
- 加锁保护
dirty - 若
dirty为nil,先从read初始化(过滤已删除条目) - 写入 / 更新
dirty中的 key-value - 标记
readOnly.amended = true(表示有新数据) - 解锁
miss 计数与 dirty 升级(性能关键):
sync.Map 设计了自适应升级机制,避免 dirty 数据过多导致读性能下降:
- 每次从
read未命中、需访问dirty时,misses++ - 当
misses >= len(dirty)时触发升级:- 原子操作将
dirty赋值给read - 置
dirty = nil、misses = 0 - 此时所有读操作又能无锁访问新的
read数据
- 原子操作将
Interface
intercface底层实现
interface有两种数据结构:eface和iface
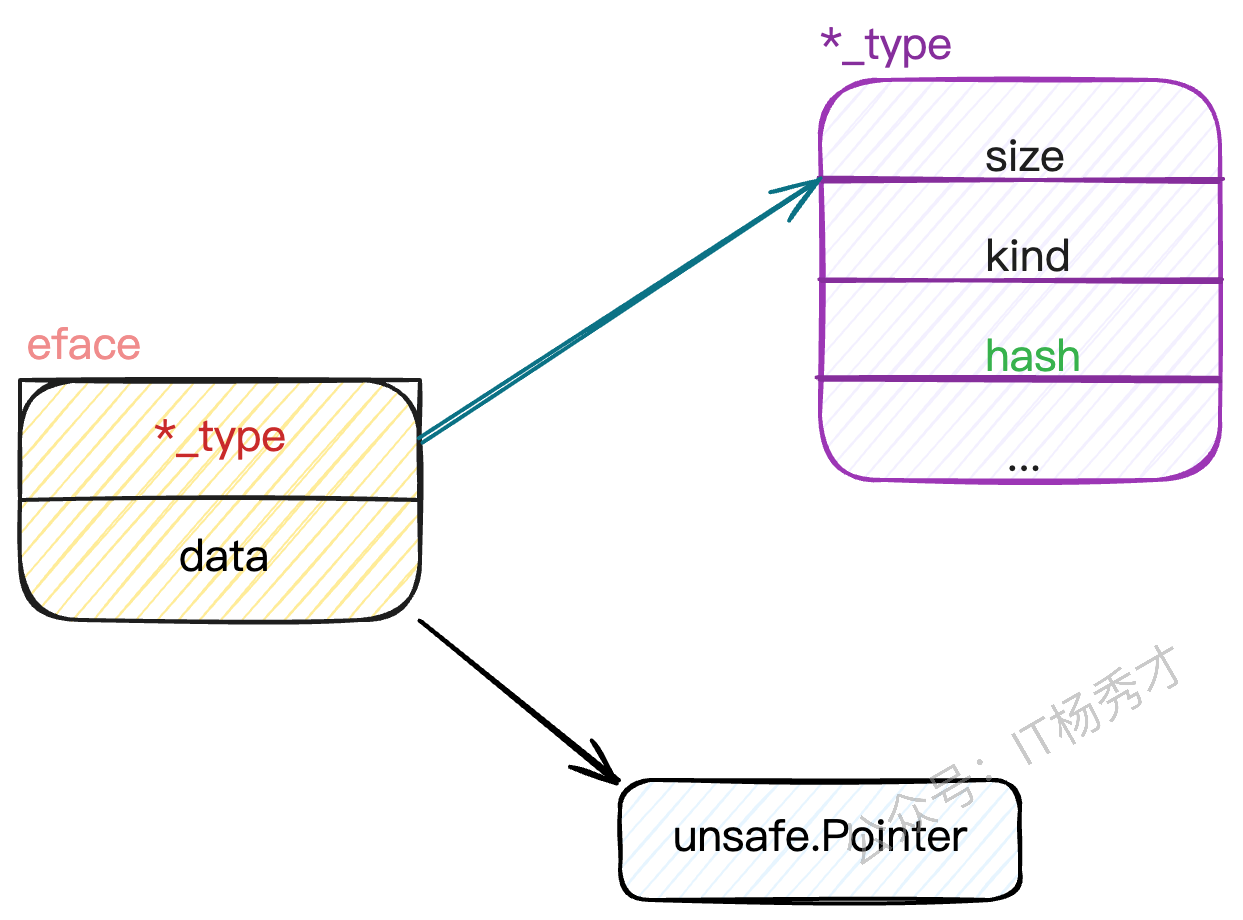
eface
空接口
两个指针:_type 指向类型信息, data指向实际数据
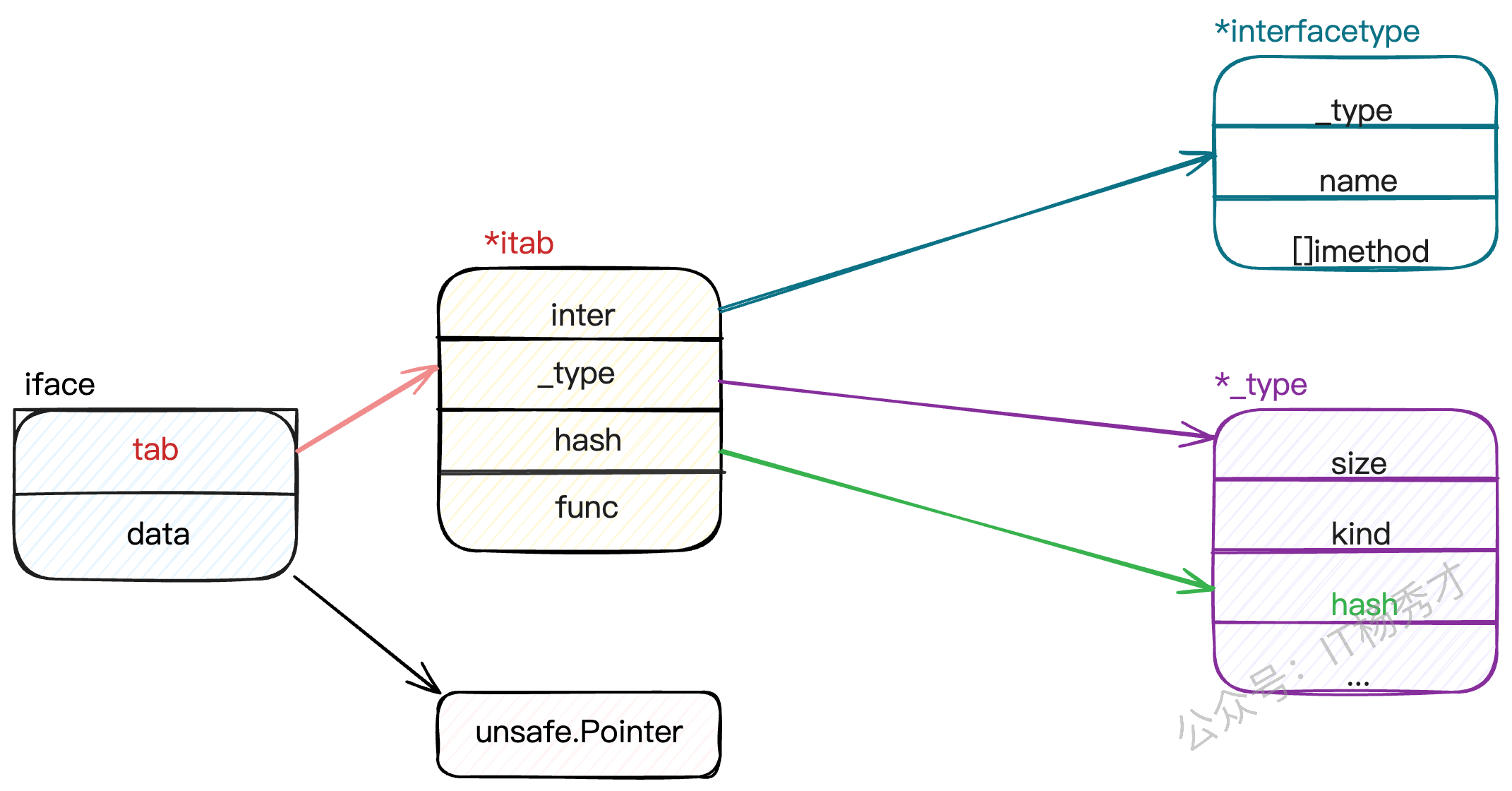
iface
非空接口 itab是核心,存储了接口类型、具体类型(动态类型)、方法表 方法表是个函数指针数组,保存了该类型实现的所有接口方法的地址
1type itab struct {
2 inter *interfacetype // 接口本身的类型(如io.Reader)
3 _type *_type // 实现类的类型、动态类型(如os.File)
4 hash uint32
5 fun [1]uintptr // 方法指针数组 用于存储函数的内存地址 定义长度1只是负责占位,实际上runtime底层不看数组长度,直接用连续内存 存入 N个方法地址。
6}
接口的比较
- 先比 动态类型:类型不同 → 直接不相等
- 类型相同 → 再比 动态值:值相等才相等
- 如果动态类型是 不可比较类型(slice/map/func),直接 panic 崩溃 注意只有动态类型和值都为nil的时候,接口才会与nil相等
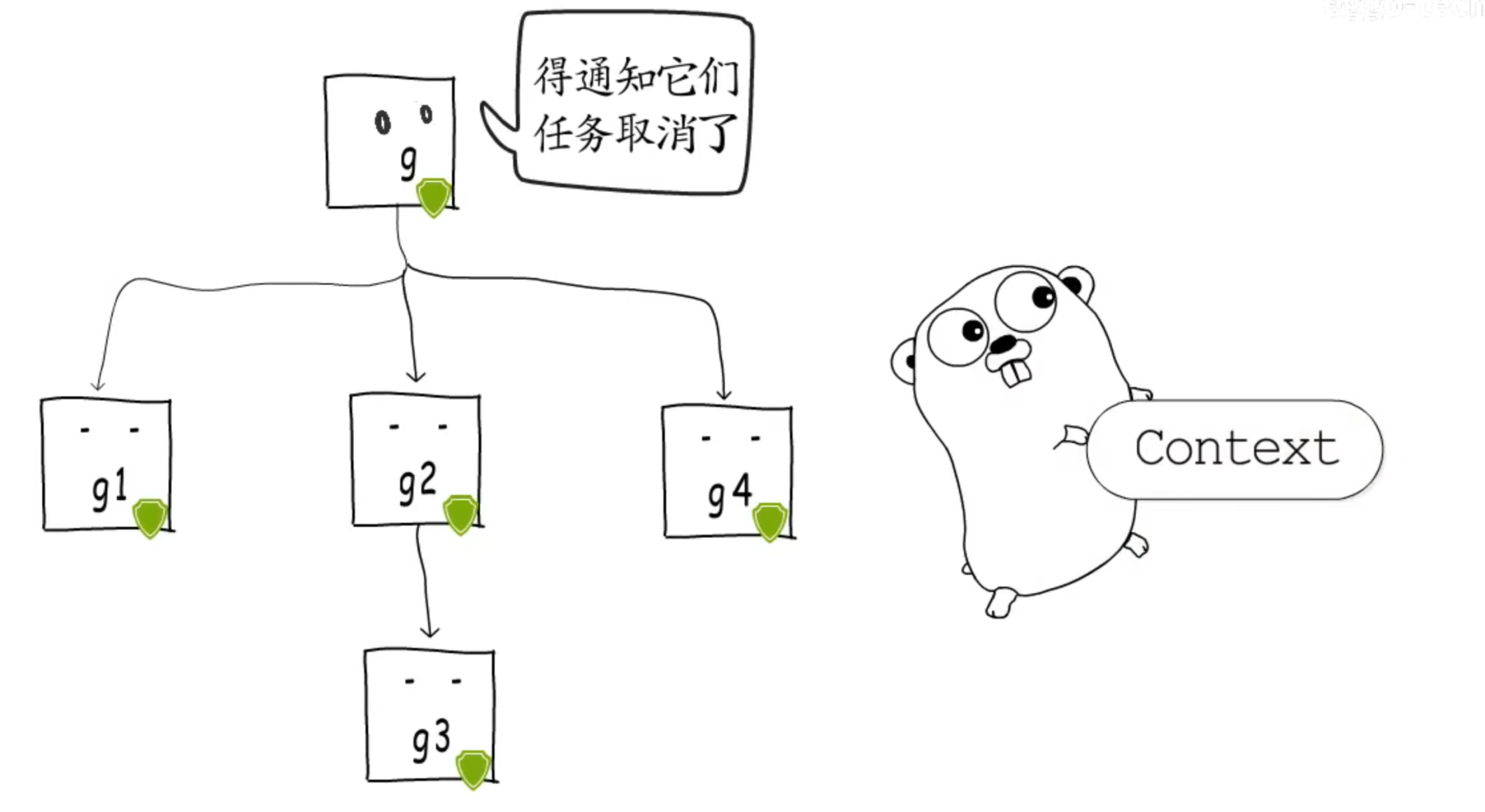
Context
干嘛用的?
超时控制、取消信号传播、请求级数据传递
是什么?
context包的主要内容可以概括为:一个接口,四种具体实现,四个方法,六个函数
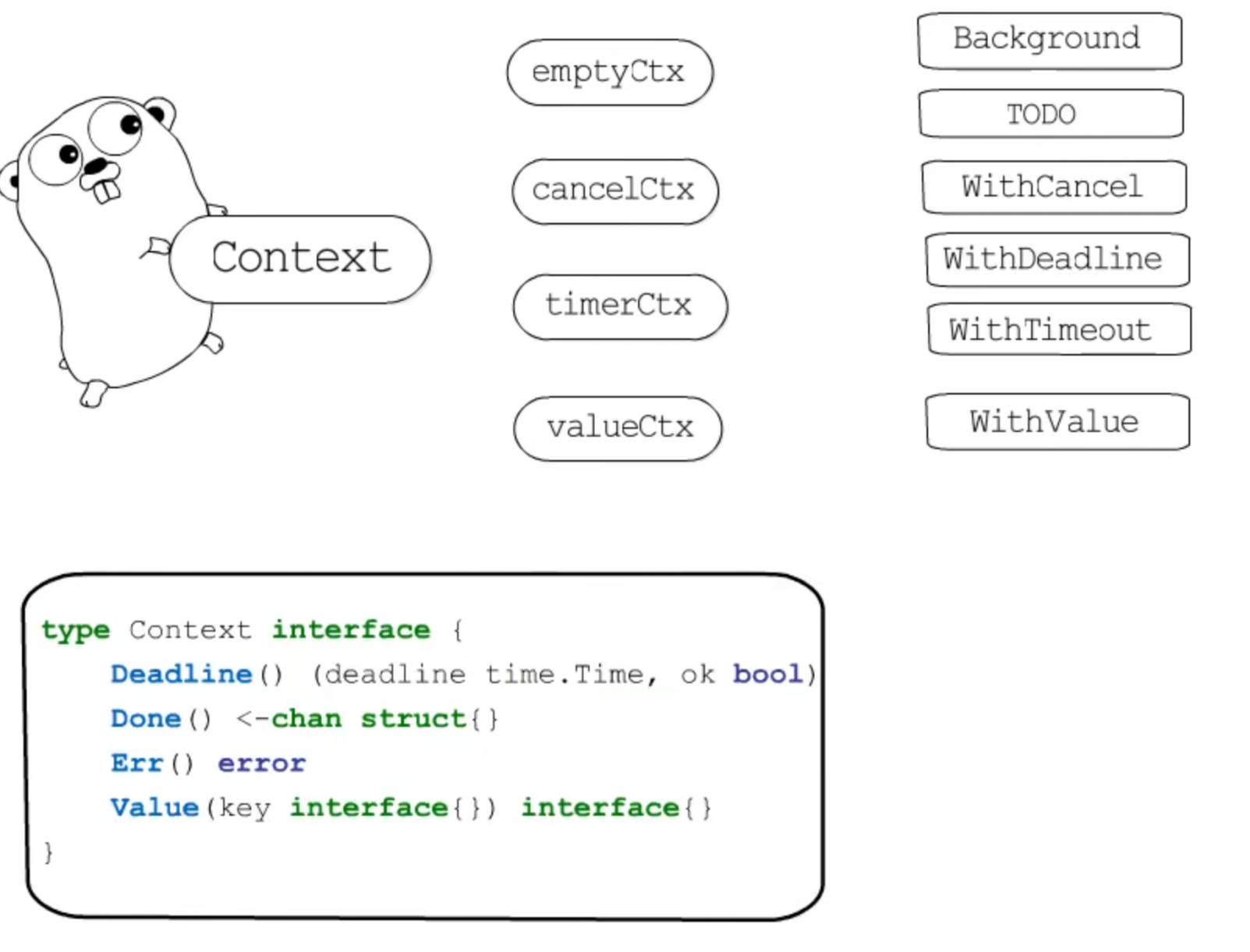
Context.Value
链式递归查找,从当前context开始,沿着父context链一直向上找,直到找到对应key或到达根context
Context如何被取消
通过channel关闭信号实现,有以下几种方式
- 主动取消,通过context.WithCancel 创建的context会返回一个cancel函数,调用就会关闭内部的done channel, 所有监听这个context的goroutine都能通过ctx.Done()收到取消信号
- 超时取消,context.WithTimeout和context.WithDeadline会启动一个定时器,到达指定时间后自动调用cancel函数触发取消
WithTimeout:传相对时长(比如:3 秒后超时)WithDeadline:传绝对时间点(比如:2026-03-26 18:00:00 超时)
- 级联取消,父context被取消时,所有子context会被自动取消,这是通过context树的结构实现的。具体的实现是在iface的data部分有一个
map[canceler]struct{}(用map模拟set集合) 用于存储以当前节点为根节点的所有可取消的context。
Go Scheduler
是go运行时的协程调度器,是go runtime的一部分,内嵌在go程序里。 它的主要工作是决定哪个goroutine在哪个线程上运行,以及何时进行上下文切换。 它包含了 GMP 模型、工作窃取(Work-Stealing)算法、全局队列、后台监控线程(sysmon)等等。
注意⚠️:Go Scheduler(调度器)是整个系统的“宏观概念”和“运行规则”,而 P 是这个系统内部的一个“实体零件”。
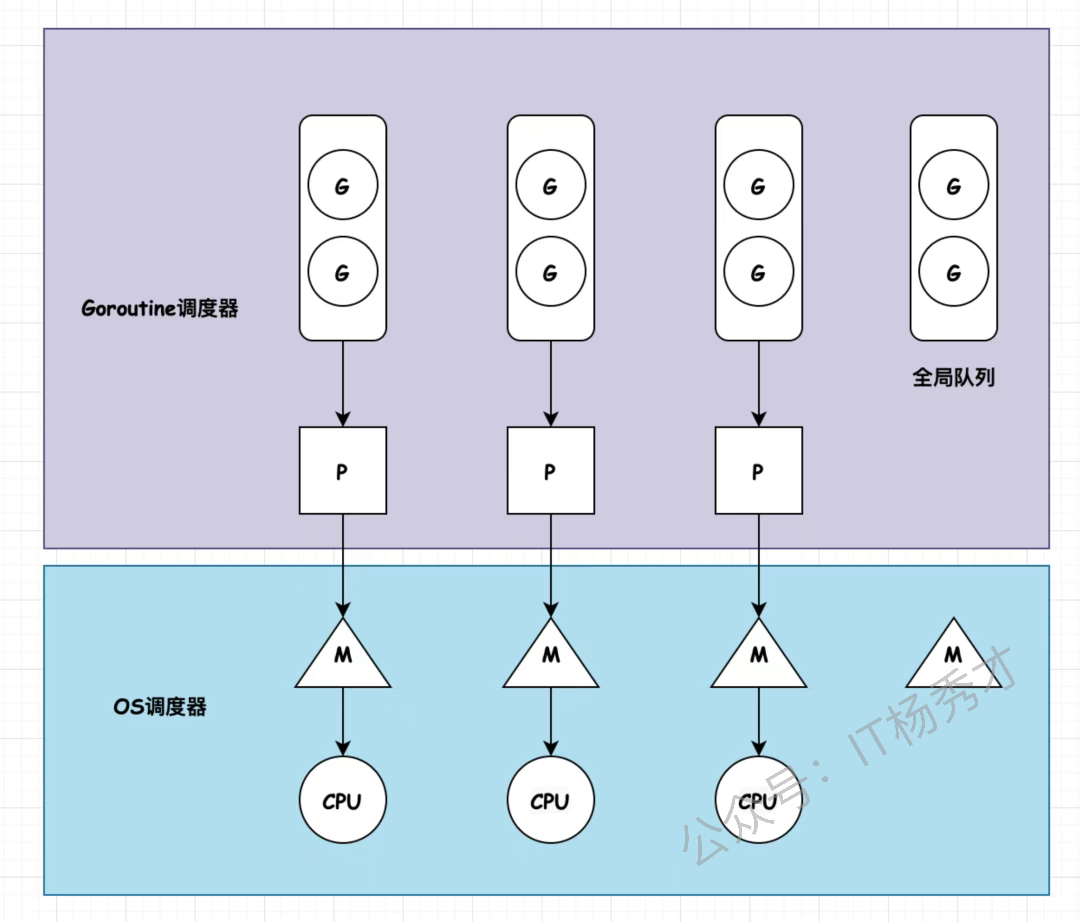
GMP模型
就是生产消费者模型嘛 G:goroutine协程 M:machine系统线程,真正干活的 P:processor逻辑处理器,负责调度G(承载 G 队列、绑定 M、提供调度上下文)
M必须绑定P才能执行G,每个P维护自己的一个本地G队列(长256),M从P的本地队列取G执行。当本地队列为空时,M会按优先级从全局队列(GRQ)、网络轮询器(netpoll)、其他P队列中窃取。
这个模型让go能在少量线程上调度海量的goroutine,是go高并发的基础
M寻找可运行G的过程
- 用CAS高效查本地队列,从当前P的LRQ里runqget一个G
- 加锁查全局队列
- 去网络轮询器里看看有没有因为网络IO阻塞的G
- 实在没有,就随机找一个别的P,从那里偷一半回来(也是CAS机制)
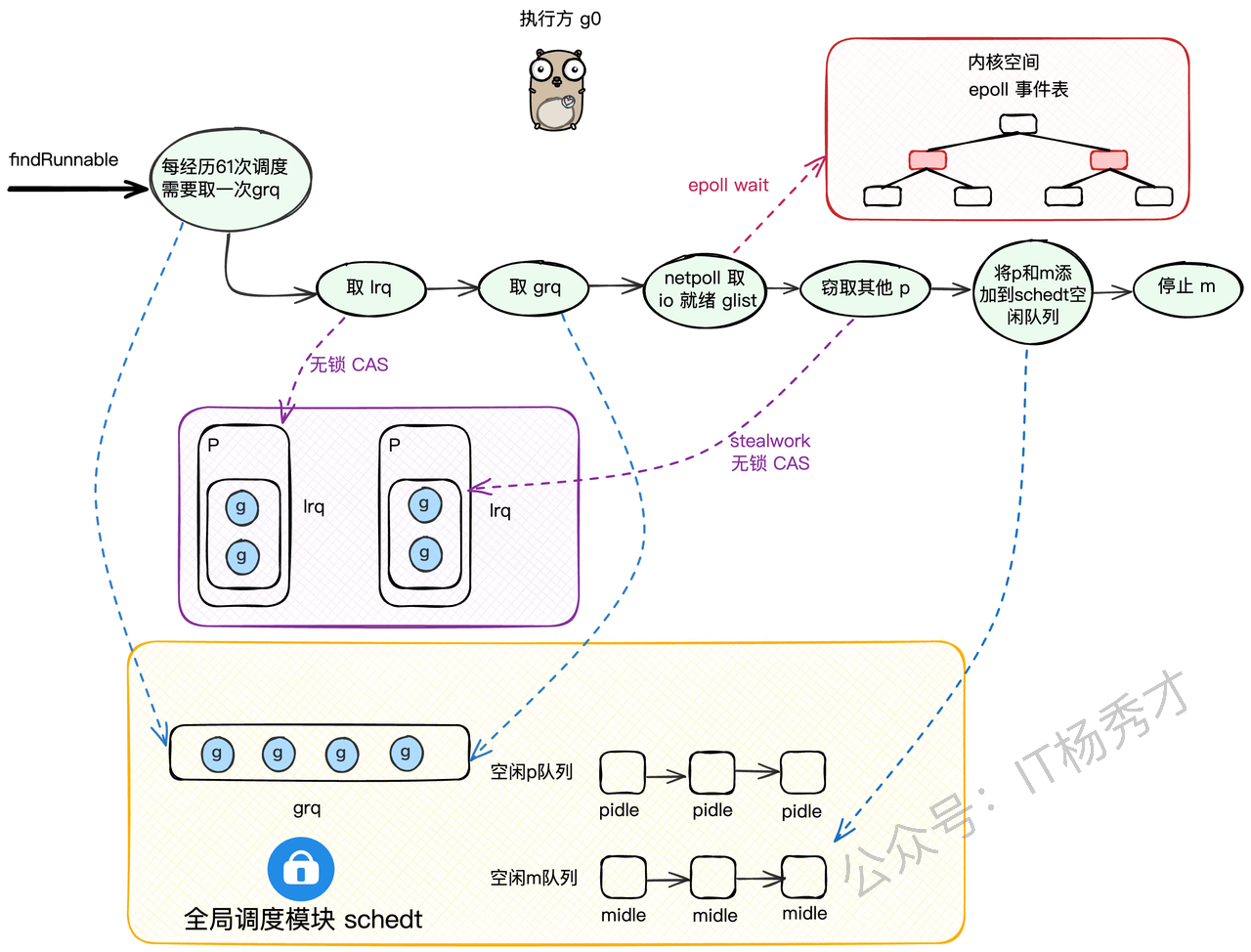
发生调度的时机
- 等待读取或写入未缓冲的通道
- 由于time.Sleep()而等待
- 等待互斥量释放
- 发生系统调用
1. 主动让出: Gosched() 2. 协作:函数调用、栈扩容 3. 阻塞:chan、锁、sleep、网络IO 4. 系统调用:进入/退出 syscall 5. 抢占:执行超 10ms(1.14+) 6. GC:STW、栈扫描 7. 均衡:work stealing
能否去掉P层
理论上GMP中可以去掉P 去P的影响:所有M都要从全局队列中获取goroutine,这就需要全局锁保护,高并发场景调度效率很低
P用CAS实现了无锁的本地调度。每个P维护独立的本地队列,大大减少了锁竞争
垃圾回收
gc只处理堆区域的内存空间
难点
- 对象消失问题:标记过程中,如果用户程序删除了引用路径,实际还是可达,被误删咋办
- 新对象处理:标记过程中新分配了对象如何着色呢?如果标记为白色可能会被误回收,直接标记为黑色可能造成浮动垃圾
mark and sweep算法
go 1.3- 之前 第一步,暂停程序业务逻辑,分类出可达和不可达的对象,然后做上标记。 第二步 , 开始标记,程序找出它所有可达的对象,并做上标记。 第三步 , 标记完了之后,然后开始清除未标记的对象。 操作非常简单,但是有一点需要额外注意:mark and sweep 算法在执行的时候,需要程序暂停!即 STW(stop the world),STW 的过程中,CPU 不执行用户代码,全部用于垃圾回收,这个过程的影响很大,所以 STW 也是一些回收机制最大的难题和希望优化的点。所以在执行第三步的这段时间,程序会暂定停止任何工作,卡在那等待回收执行完毕。
第四步 , 停止暂停,让程序继续跑。然后循环重复这个过程,直到 process 程序生命周期结束。
以上便是标记 - 清除(mark and sweep)回收的算法。
缺点
- STW,stop the world;让程序暂停,程序出现卡顿 (重要问题);
- 标记需要扫描整个 heap;
- 清除数据会产生 heap 碎片。
三色标记法
go1.5+ GC 把所有对象分成 3 种颜色,颜色越深越活跃
- 白色:未扫描 → 疑似垃圾(最后会被回收)
- 灰色:正在扫描 → 活着
- 黑色:扫描完成 → 确定活着 正常流程:
- 所有对象一开始都是 白色
- GC 从根对象(栈、全局变量)开始扫,标为 灰色
- 扫完对象,标为 黑色
- 最后剩下的 白色对象 = 垃圾,直接回收
什么是根对象?
- 全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量
- 执行栈:每个goroutine都包含自己的执行栈
- 寄存器:寄存器的值可能表示一个指针
屏障机制
解决什么问题?
GC 正在后台标记「哪些对象是活着的、有用的」结果代码突然改了对象的指向导致 GC 没看到这个有用的对象,把它当成垃圾回收了→ 程序直接崩溃! 就是防止误删
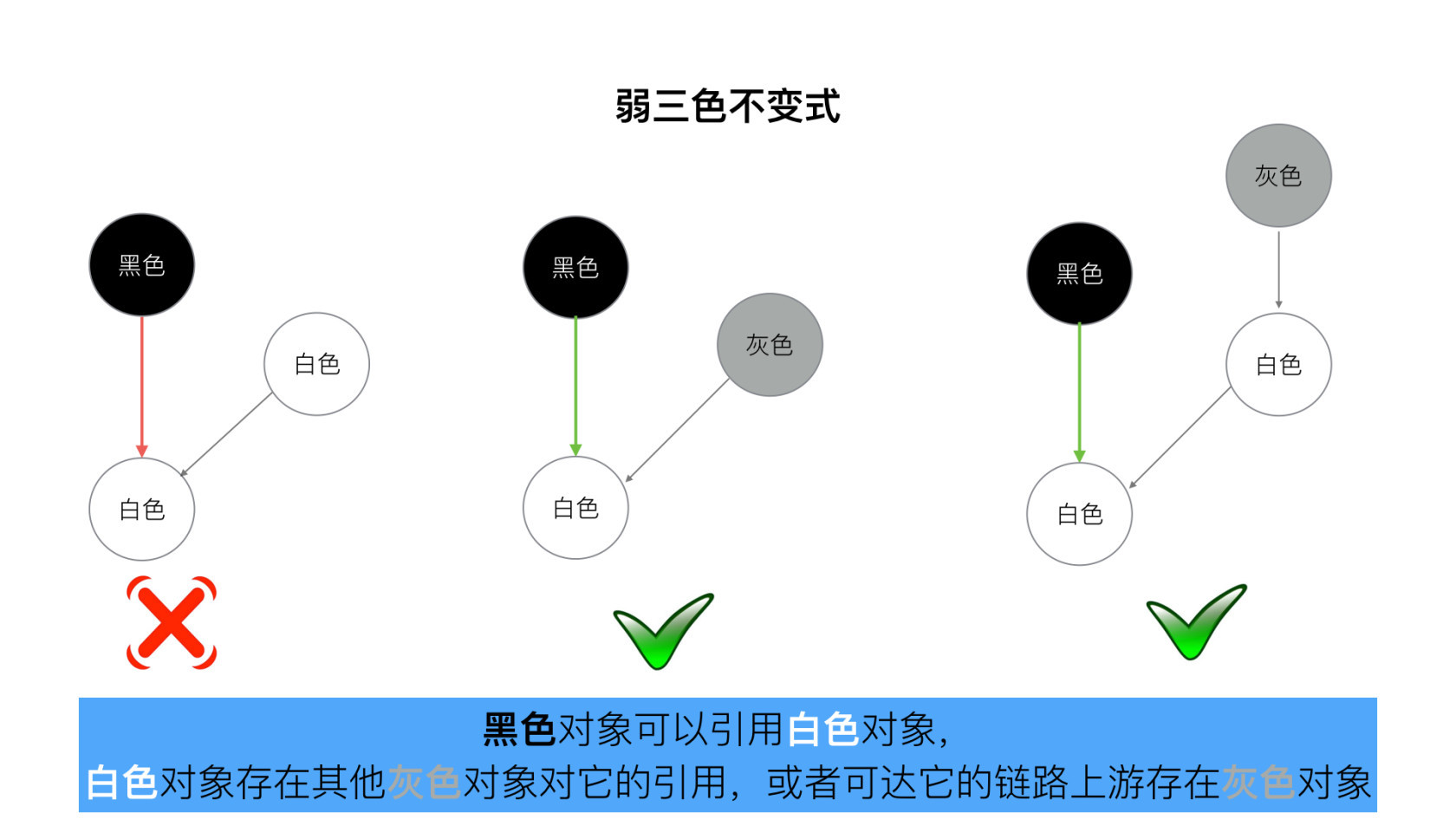
强弱三色不变式
我们让 GC 回收器,满足下面两种情况之一时,即可保对象不丢失。
- 强三色不变式 不存在黑色对象引用到白色对象的指针。防止白色误删
- 弱三色不变式
所有被黑色对象引用的白色对象都处于灰色保护状态。
插入屏障
具体操作: 在 A 对象引用 B 对象的时候,B 对象被标记为灰色。(将 B 挂在 A 下游,B 必须被标记为灰色) 满足: 强三色不变式. (不存在黑色对象引用白色对象的情况了, 因为白色会强制变成灰色)
栈空间销毁极快、访问频繁,加写屏障会导致性能暴跌,所以只能靠STW暂停全局来防止用户程序并发修改对象引用的问题(不冻结就会扫错导致误删) 而因为堆太大了,不可能跟着栈一起 STW,只能并发扫堆; 并发扫堆就必须写屏障,否则 GC 会直接错标、崩程序。 所以最后的总开销只有每个 goroutine 栈就几 KB~ 几 MB,扫一遍只要几微秒 / 毫秒,所以可以接受
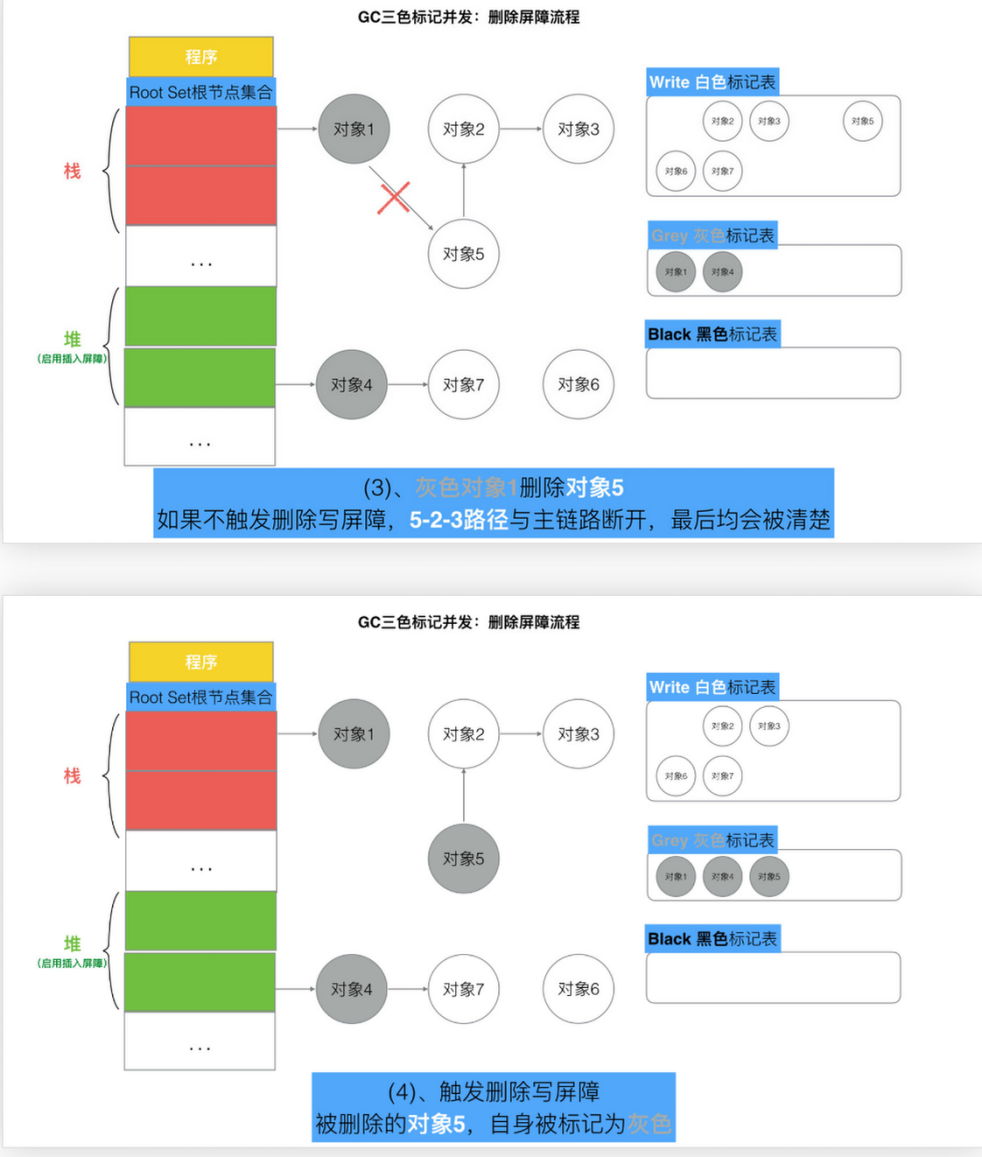
删除屏障
具体操作: 被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。
满足: 弱三色不变式. (保护灰色对象到白色对象的路径不会断)
混合写屏障
Go 1.8 之后用了混合写屏障,完美解决两个问题:
- 业务代码修改对象引用 → 立刻标记存活
- 不需要扫描栈(提升性能)
- 全程不卡住业务代码(GC 无停顿)
流程如下: 1、GC 开始将栈上的对象全部扫描并标记为黑色 (之后不再进行第二次重复扫描,无需 STW), 2、GC 期间,任何在栈上创建的新对象,均为黑色。 3、被删除的对象标记为灰色。 4、被添加的对象标记为灰色。
满足: 变形的弱三色不变式.
总结GC
GoV1.3- 普通标记清除法,整体过程需要启动 STW,效率极低。
GoV1.5- 三色标记法, 堆空间启动写屏障,栈空间不启动,全部扫描之后,需要重新扫描一次栈 (需要 STW),效率普通
GoV1.8 - 三色标记法,混合写屏障机制, 栈空间不启动,堆空间启动。整个过程几乎不需要 STW,效率较高。