环境介绍
- OS: Ubuntu 24.04.2 LTS
- GPU: NVIDIA GeForce GTX 1050 Ti
- immich: docker compose部署
- date: 2025-10-05
- network: need proxy
模型下载
下载地址: immich-app/XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k at main
下载须知:
- 给下载目标路径的目录预留充足磁盘空间,>20GB。
- 需安装git-lfs(管理git大文件的拓展)
1sudo apt-get install git-lfs
2
3df -h ~/path # 查看仓库所在分区的空间
4
5#若目录下磁盘空间不足,迁移到别的目录,以下是迁移指令
6rsync -av 原路径 目标路径
7# `-a`:归档模式,保留文件权限、时间戳等所有属性
8# `-v`:显示复制进度
9
10rm -rf ~/path
11
12#断点续连
13git restore --source=HEAD :/
把下载来的模型放在clip文件夹以下的位置:
1path-to-your-dir
2└── modelcache
3 └── clip
4 └── XLM-Roberta-Large-ViT-H-14__frozen_laion5b_s13b_b90k
硬件加速
ps:硬件加速对于显存要求较高,如果你在尝试以下操作后,机器学习容器日志报错显存不足,建议使用更轻量的模型,或者换回cpu。
更换独显
1#查询电脑所有显卡信息
2lspci | grep -i vga
3
4#查询目前使用显卡
5prime-select query
6
7#更换到NVIDIA独立显卡
8sudo prime-select nvidia
9
10#之后加速完毕,用此命令回退到按需选择显卡
11sudo prime-select on-demand
更改后需重启
显卡驱动
显卡换好了,检查一下驱动:
先输入以下命令,看一下显卡驱动是否正常
1nvidia-smi
若出现NVIDIA-SMI has failed的报错,先打驱动:
1sudo ubuntu-drivers autoinstall
重启后再次检查驱动是否正常。
容器调用
想要docker容器调用GPU,我们还需要按以下步骤操作:
1# 添加密钥和仓库
2curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
3
4curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
5 sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
6 sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
7
8#安装nvidia-container-toolkit
9sudo apt-get update
10sudo apt-get install -y nvidia-container-toolkit
运行测试容器,如果输出与宿主机一样的gpu信息,说明成功!此时我们的容器已经可以成功启用硬件加速。
1docker run --rm --gpus all nvidia/cuda:12.6.0-base-ubuntu24.04 nvidia-smi
配置immich
Immich 支持多种 GPU 加速类型,需根据硬件选择:
- NVIDIA 显卡:选择
cuda - AMD 显卡:选择
rocm - Intel 显卡 / NPU:选择
openvino(普通 Intel 设备)或openvino-wsl(WSL2 环境的 Intel 设备) - ARM 架构设备(如瑞芯微 RK3588 等):选择
rknn - ARM 设备(带 NN 加速):选择
armnn
配置docker-compose
启用硬件加速的情况:
在docker-compose.yml同级目录输入以下指令,下载hwaccel.ml.yml:
1wget https://github.com/immich-app/immich/blob/main/docker/hwaccel.ml.yml
docker-compose.yml:
1 #只展现机器学习部分
2 immich-machine-learning:
3 container_name: immich_machine_learning
4 # For hardware acceleration, add one of -[armnn, cuda, rocm, openvino, rknn] to the image tag.
5 # Example tag: ${IMMICH_VERSION:-release}-cuda
6 image: ghcr.io/immich-app/immich-machine-learning:${IMMICH_VERSION:-release}-cuda
7 #extends:
8 #file: hwaccel.ml.yml
9 #service: cuda
10
11 volumes:
12 #注意这里要换成你自己存放模型的目录
13 - './modelcache:/cache'
14 env_file:
15 - .env
16 restart: always
17 networks:
18 - my-network
19 healthcheck:
20 disable: false
21 deploy:
22 resources:
23 reservations:
24 devices:
25 - driver: nvidia
26 count: 1
27 capabilities:
28 - gpu
不启用的情况:
docker-compose.yml:
1 immich-machine-learning:
2 container_name: immich_machine_learning
3 image: ghcr.io/immich-app/immich-machine-learning:${IMMICH_VERSION:-release}
4 volumes:
5 - './modelcache:/cache'
6 env_file:
7 - .env
8 restart: always
9 networks:
10 - my-network
11 healthcheck:
12 disable: false
13 deploy:
14 resources:
15 limits:
16 cpus: '3' # 分配3核CPU
17 memory: 4G # 分配6GB内存(避免CPU加载模型时内存不足)
启用智能搜索
输入你的模型名
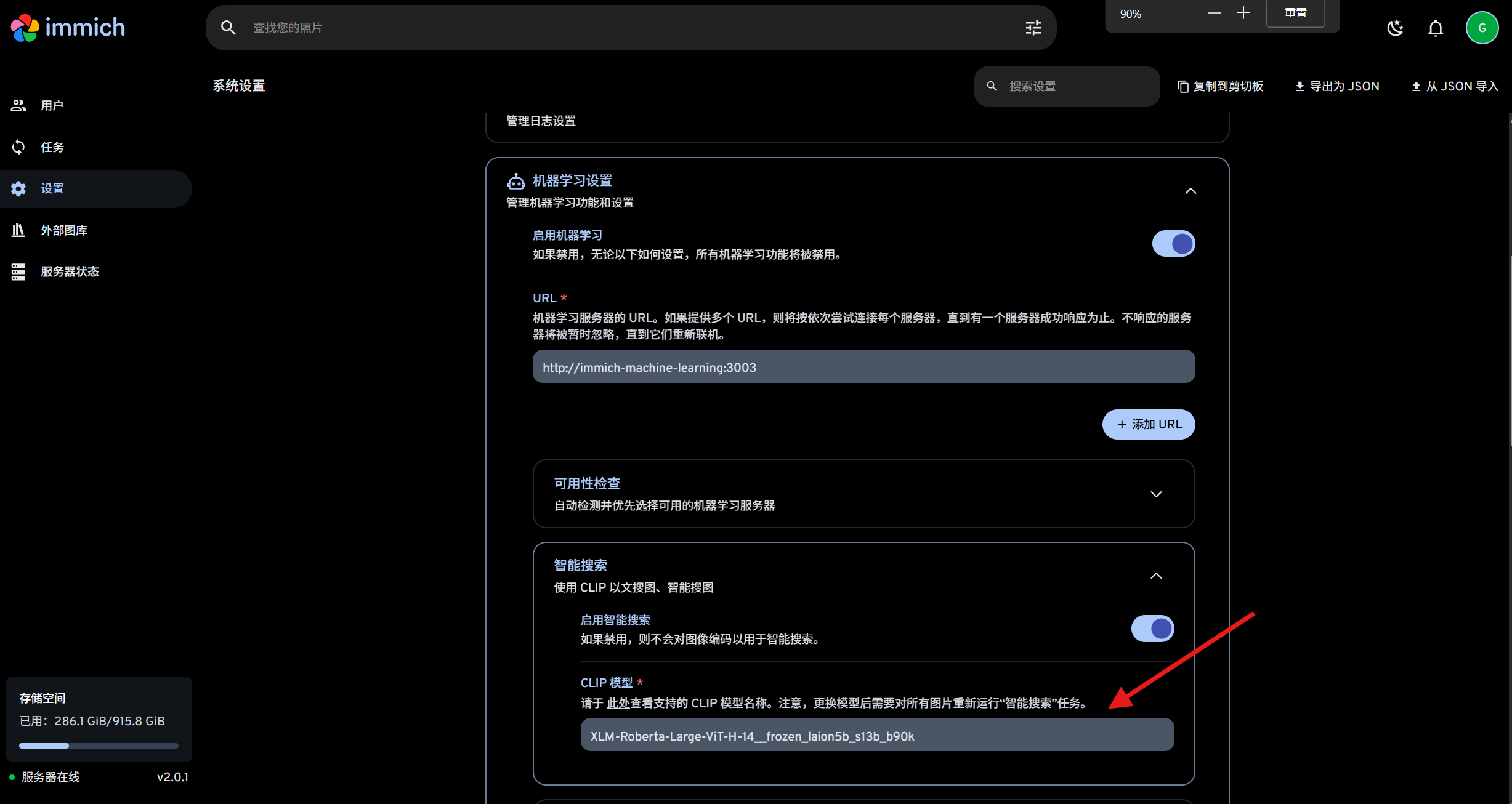
然后进行任务,点击全部。
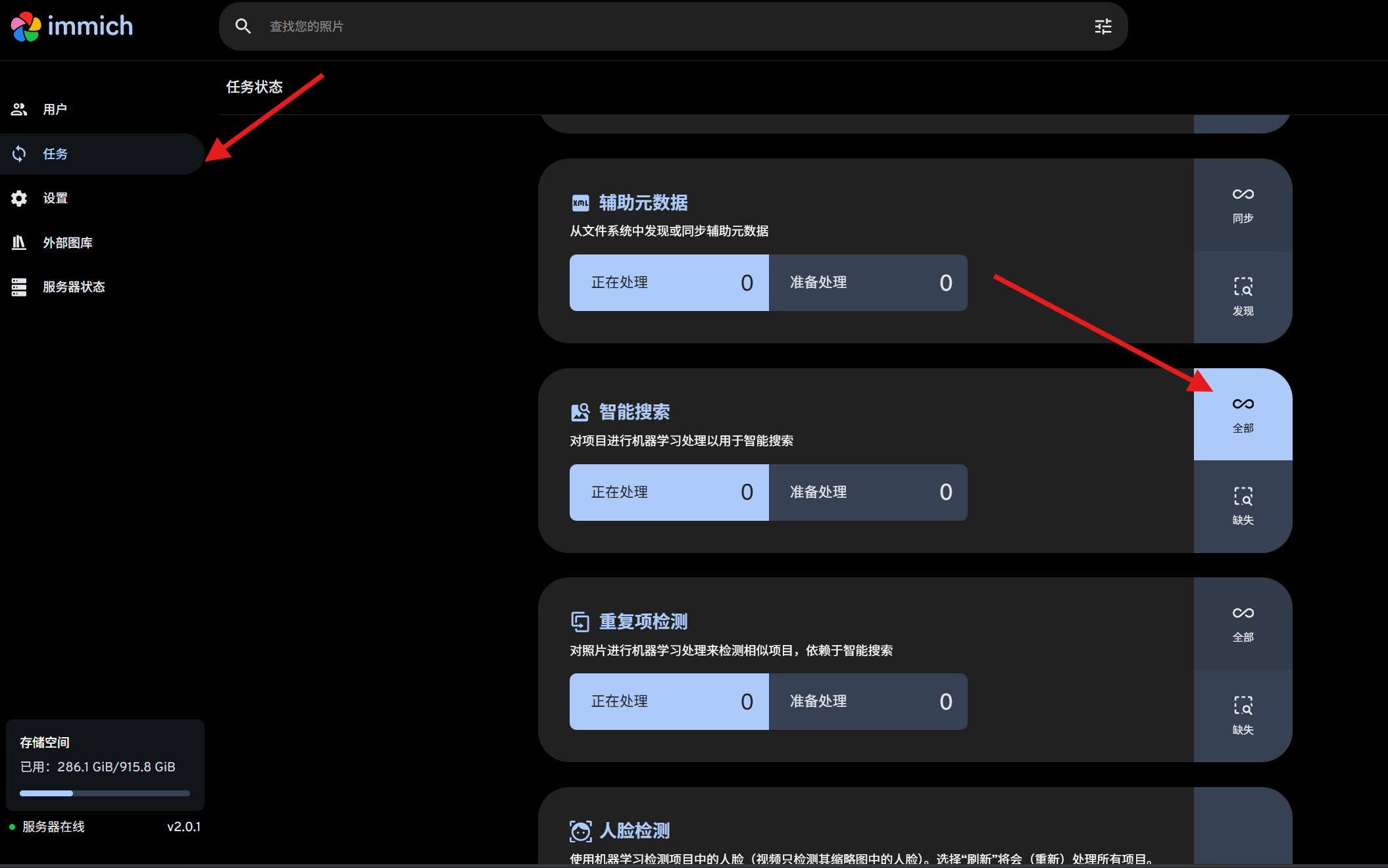
耐心等待机器学习完毕……
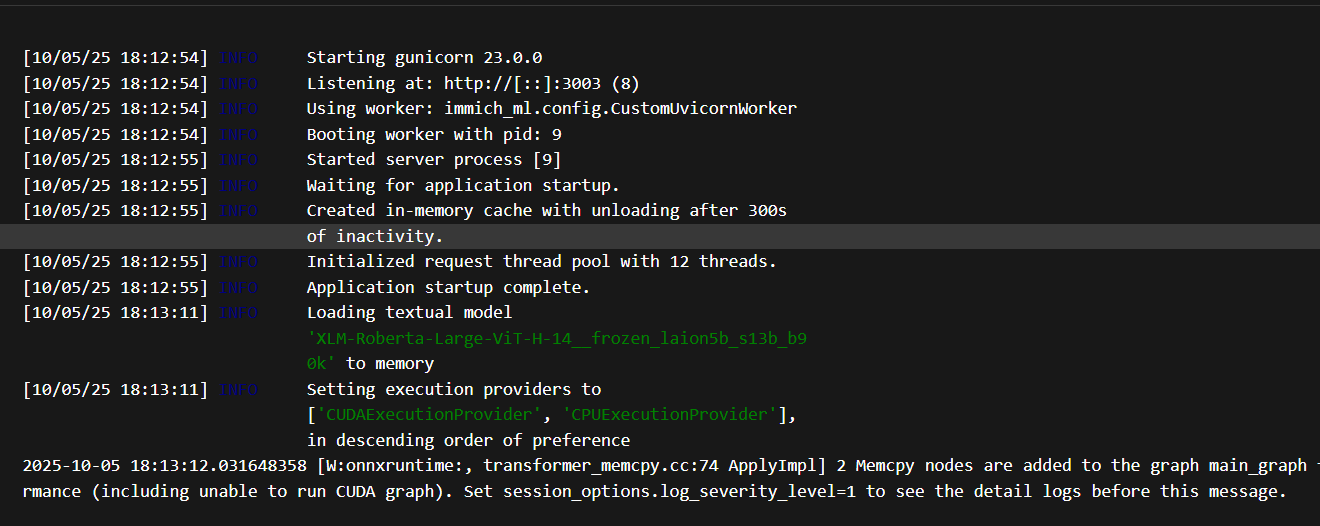
如果你开启了GPU加速,去 immich_machine_learning 容器的日记里看一下,是否出现跟以下类似的输出,Setting execution providers to ['CUDAExecutionProvider', 'CPUExecutionProvider'] 说明服务正在优先使用GPU,这就说明我们的配置正确无误!
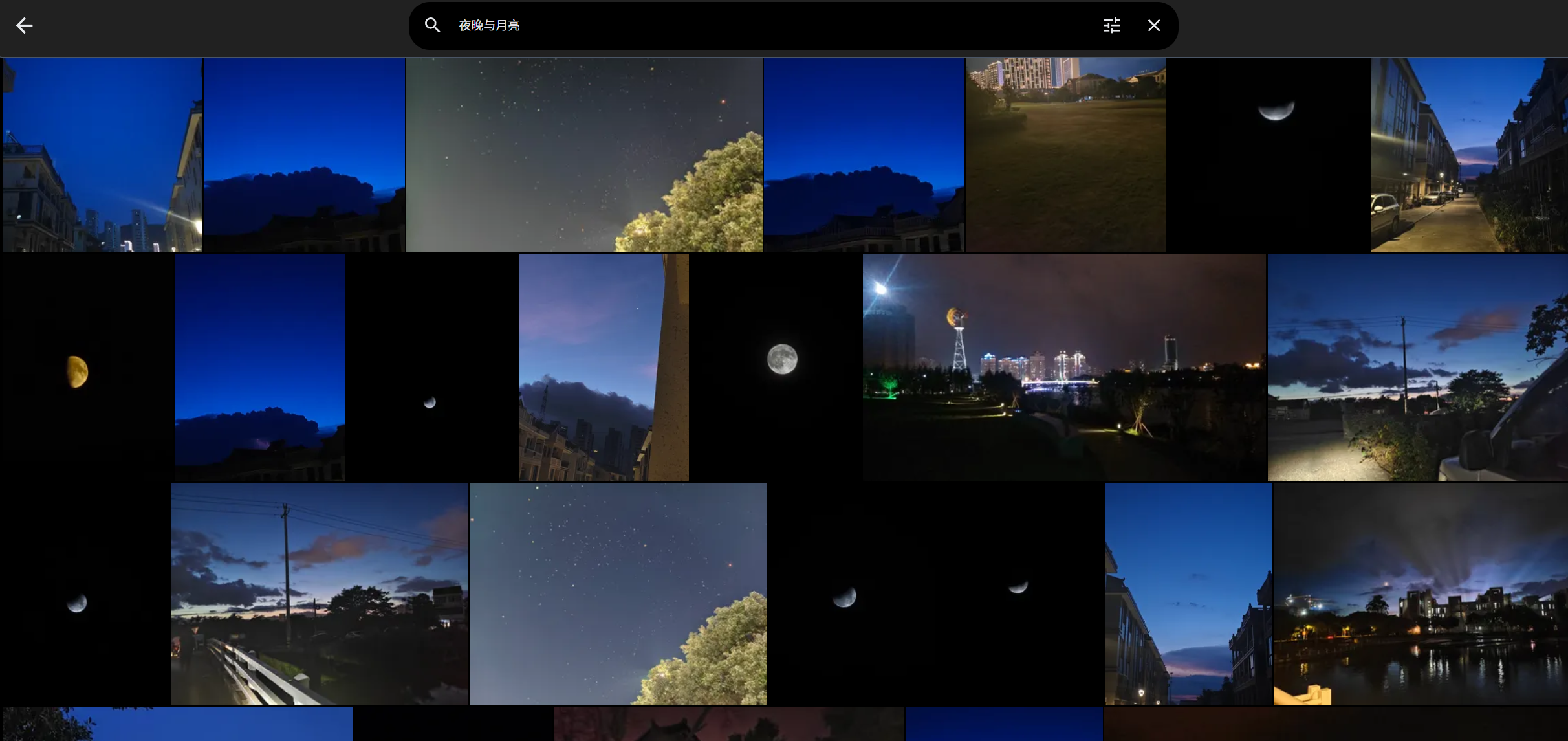
最后,搜索你想要的关键字,哒哒,成功啦!
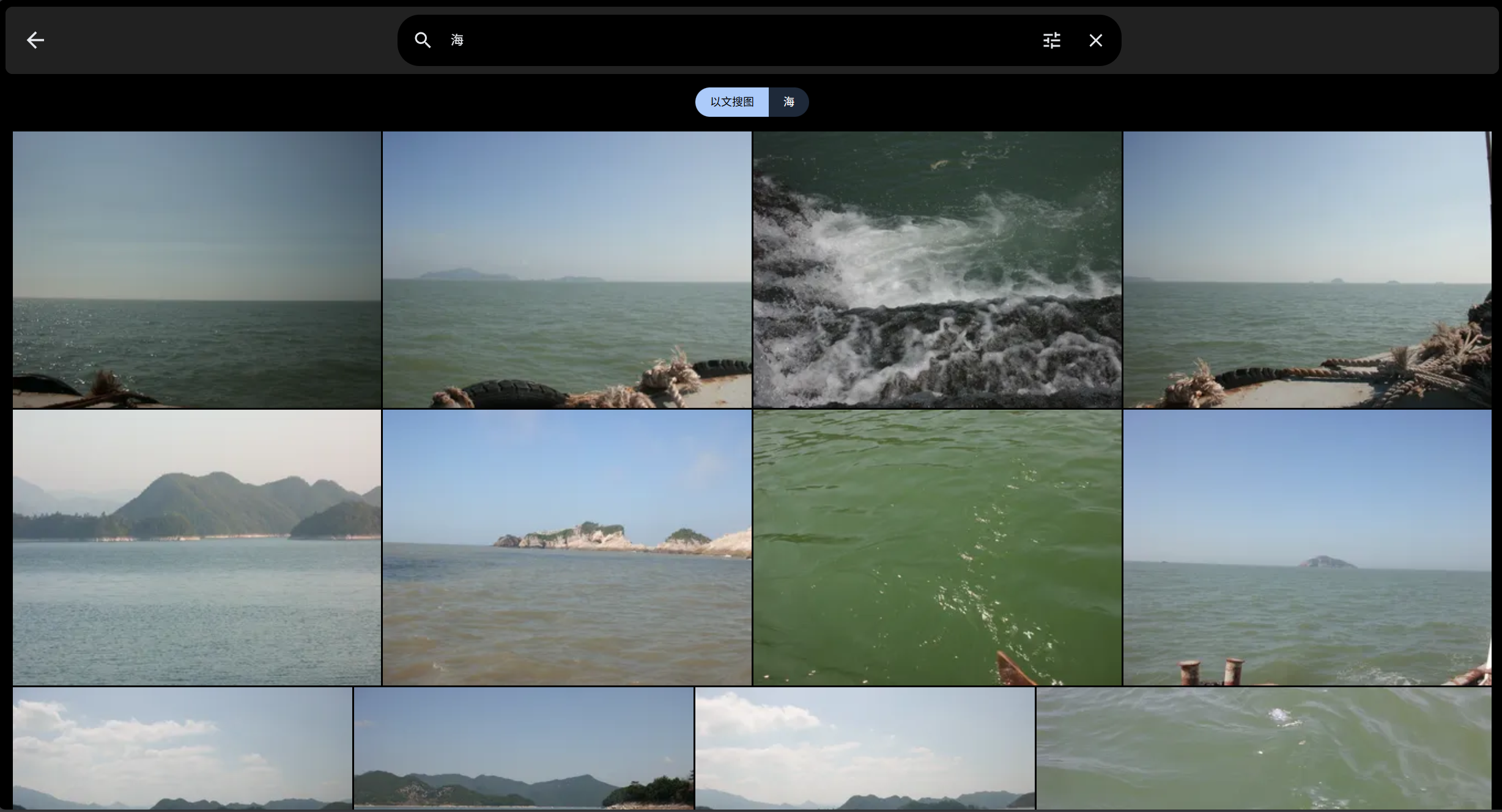
配置人脸识别也是一样的步骤,由于博主服务器的显存捉襟见肘,这里就不演示啦。😭 欢迎评论区交流~~~
参考文章
鸣谢: